Horizontal Autoscaling of Shoot Nodes
Every Shoot cluster that has at least one worker pool
with minimum < maximum nodes configuration will get a cluster-autoscaler deployment.
Gardener is leveraging the upstream community Kubernetes
cluster-autoscaler component.
Which means that logging of Kubernetes cluster-autoscaler is the same.
Scaling of Shoot nodes are defined in their yaml configuration in part.
In our stack the cluster-autoscaler in the Shoot namespace on the Seed cluster
is responsible for scaling up and down pod deployment.
Scaling Up
Scale-up creates a watch on the API server looking for all pods.
It checks for any unschedulable pods every 10 seconds (configurable by --scan-interval flag).
A pod is unschedulable when the Kubernetes scheduler is unable to find a node
that can accommodate the pod. For example, a pod can request more CPU
that is available on any of the cluster nodes. Unschedulable pods
are recognized by their PodCondition. Whenever a Kubernetes scheduler fails to find
a place to run a pod, it sets "schedulable" PodCondition to false
and reason to "unschedulable".
If there are any items in the unschedulable pods list,
Cluster Autoscaler tries to find a new place to run them.
It is assumed that the underlying cluster is run on top of some kind of node groups. Inside a node group, all machines have identical capacity and have the same set of assigned labels. Thus, increasing a size of a node group will create a new machine that will be similar to these already in the cluster – they will just not have any user-created pods running (but will have all pods run from the node manifest and daemon sets).
It may take some time before the created nodes appear in Kubernetes.
It almost entirely depends on the cloud provider and the speed of node provisioning,
including the TLS bootstrapping process. Cluster Autoscaler expects requested nodes
to appear within 15 minutes (configured by --max-node-provision-time flag.)
After this time, if they are still unregistered, it stops considering them in simulations
and may attempt to scale up a different group if the pods are still pending.
It will also attempt to remove any nodes left unregistered after this time.
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
…
maxSurge: 1 - how much nodes could be scaled up in one iteration
maxUnavailable: 0
maximum: 3 - upper limit to which maximally could be Shoot nodes extended
minimum: 1 - number of nodes which is the minimal (initial deployment status)
Example
Shoot name: mcm13
Number of nodes: 1
Node resources: 2 CPU 4GB Ram
Sacling configuration:
maxSurge: 1
maxUnavailable: 0
maximum: 2
minimum: 1
Gardener project name: dev
Name of seed namespace for Shoot: shoot--dev--mcm13
Lets consider we have 1 node Shoot cluster with 2 CPU and 4 GB of RAM. We will deploy on this Shoot cluster there pod with requests for resources which is higher than what Shoot node could offer.
apiVersion: v1
kind: Pod
metadata:
name: task-ha
spec:
containers:
- name: ha-exaple
image: nginx
ports:
- containerPort: 80
name: "http-server"
resources:
requests:
cpu: "1500m"
memory: "2Gi"
On the Shoot is currently running some load and could not provide to pod resources mentioned in resource part and therefore autoscaling will be activated.
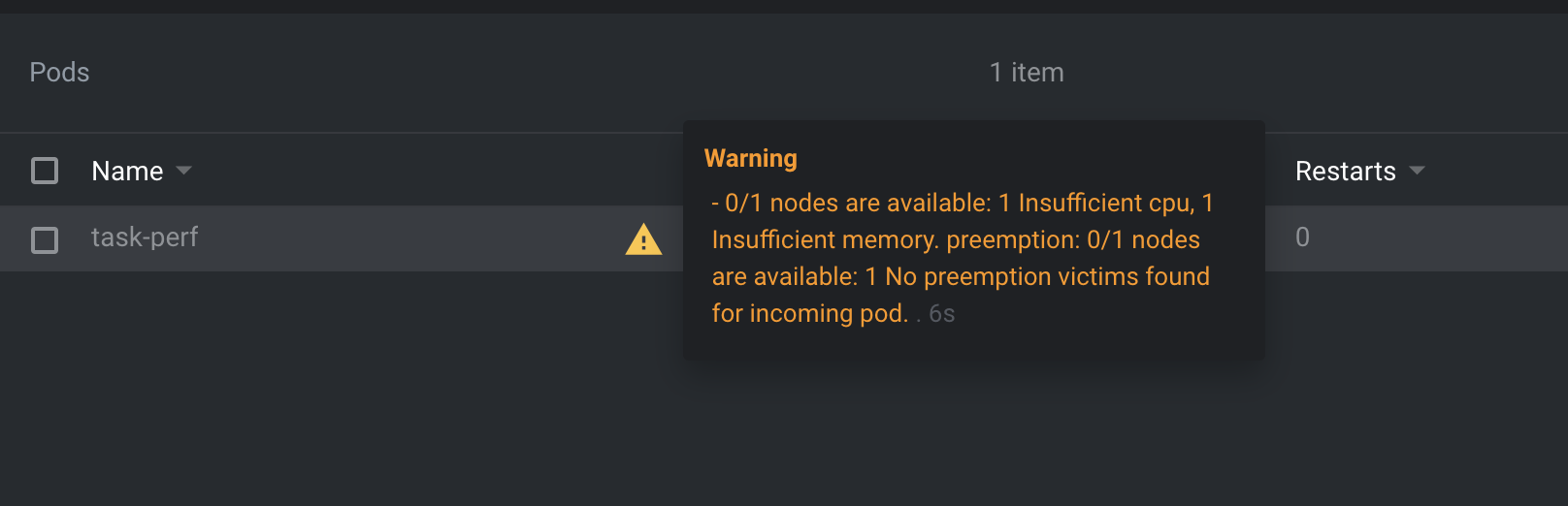
Below you can find logs from cluster-autoscaler-xxxxxx-xxx pod
when its activating scale-up
I0203 12:25:13.198285 1 klogx.go:86] Pod default/task-perf is unschedulable
I0203 12:25:13.198560 1 waste.go:55] Expanding Node Group Shoot--dev--mcm13-wrk-z1 would waste 25.00% CPU, 47.93% Memory, 36.47% Blended
I0203 12:25:13.198581 1 scale_up.go:468] Best option to resize: Shoot--dev--mcm13-wrk-z1
I0203 12:25:13.198589 1 scale_up.go:472] Estimated 1 nodes needed in Shoot--dev--mcm13-wrk-z1
I0203 12:25:13.198611 1 scale_up.go:595] Final scale-up plan: [{Shoot--dev--mcm13-wrk-z1 1->2 (max: 2)}]
I0203 12:25:13.198626 1 scale_up.go:691] Scale-up: setting group Shoot--dev--mcm13-wrk-z1 size to 2
When you check status of pod by kubectl get pod/cluster-autoscaler-xxxxxx-xxx
in section status you should see False status with reason reason: Unschedulable
status:
phase: Pending
conditions:
- type: PodScheduled
status: 'False'
lastProbeTime: null
lastTransitionTime: '2023-02-03T12:25:04Z'
reason: Unschedulable
message: >-
0/1 nodes are available: 1 Insufficient cpu, 1 Insufficient memory.
preemption: 0/1 nodes are available: 1 No preemption victims found for
incoming pod.
After some time you can see that cluster has 2 nodes

And than pod could be safely scheduled.

Scaling Down
Every 10 seconds (configurable by --scan-interval flag), if no scale-up is needed,
Cluster Autoscaler checks which nodes are unneeded.
A node is considered for removal when all below conditions hold:
The sum of cpu and memory requests of all pods running on this node (DaemonSet pods
and Mirror pods are included by default but this is configurable with --ignore-daemonsets-utilization
and --ignore-mirror-pods-utilization flags) is smaller than 50% of the node's allocatable.
(Before 1.1.0, node capacity was used instead of allocatable.)
Utilization threshold can be configured using --scale-down-utilization-threshold flag.
All pods running on the node (except these that run on all nodes by default, like manifest-run pods or pods created by daemonsets) can be moved to other nodes. See What types of pods can prevent CA from removing a node? section for more details on what pods don't fulfill this condition, even if there is space for them elsewhere. While checking this condition, the new locations of all movable pods are memorized. With that, Cluster Autoscaler knows where each pod can be moved, and which nodes depend on which other nodes in terms of pod migration. Of course, it may happen that eventually the scheduler will place the pods somewhere else.
It doesn't have scale-down disabled annotation (see How can I prevent Cluster Autoscaler from scaling down a particular node?)
If a node is unneeded for more than 10 minutes, it will be terminated.
(This time can be configured by flags – please see I have a couple of nodes
with low utilization, but they are not scaled down.
Why? section for a more detailed explanation.)
Cluster Autoscaler terminates one non-empty node at a time
to reduce the risk of creating new unschedulable pods.
The next node may possibly be terminated just after the first one,
if it was also unneeded for more than 10 min and didn't rely on the same nodes
in simulation (see below example scenario), but not together.
Empty nodes, on the other hand, can be terminated in bulk, up to 10 nodes at a time
(configurable by --max-empty-bulk-delete flag.)
What happens when a non-empty node is terminated? As mentioned above, all pods should be migrated elsewhere. Cluster Autoscaler does this by evicting them and tainting the node, so they aren't scheduled there again.
DaemonSet pods may also be evicted. This can be configured separately for empty
(i.e. containing only DaemonSet pods) and non-empty nodes with --daemonset-eviction-for-empty-nodes
and --daemonset-eviction-for-occupied-nodes flags, respectively.
Note that the default behavior is different on each flag: by default DaemonSet pods
eviction will happen only on occupied nodes. Individual DaemonSet pods
can also explicitly choose to be evicted (or not).
See How can I enable/disable eviction for a specific DaemonSet for more details.
Example 1
Shoot name: mcm13
Number of nodes: 1
Node resources: 2 CPU 4GB Ram
Scaling configuration:
maxSurge: 1
maxUnavailable: 0
maximum: 2
minimum: 1
Gardener project name: dev
Name of seed namespace for Shoot: shoot--dev--mcm13
Lets consider that this Shoot has currently 2 nodes after scaling up procedure described in section Scaling Up.
We will now remove pod with high resources requirements by
kubectl delete pod/task-perf (if needed specify kubeconfig of Shoot cluster
and namespace if it is not in default)
After max 5 minutes you should see in logs of cluster-autoscaler-xxxxxx-xxx:
I0203 13:10:26.954665 1 cluster.go:139] Shoot--dev--mcm13-wrk-z1-6c765-wk8gr for removal
I0203 13:10:26.955076 1 cluster.go:167] node Shoot--dev--mcm13-wrk-z1-6c765-wk8gr may be removed
I0203 13:10:36.967661 1 static_autoscaler.go:432] No unschedulable pods
I0203 13:10:36.967735 1 cluster.go:139] Shoot--dev--mcm13-wrk-z1-6c765-wk8gr for removal
I0203 13:10:36.968060 1 cluster.go:167] node Shoot--dev--mcm13-wrk-z1-6c765-wk8gr may be removed
I0203 13:10:46.980632 1 static_autoscaler.go:432] No unschedulable pods
I0203 13:10:46.980761 1 cluster.go:139] Shoot--dev--mcm13-wrk-z1-6c765-wk8gr for removal
I0203 13:10:46.981009 1 cluster.go:167] node Shoot--dev--mcm13-wrk-z1-6c765-wk8gr may be removed
When you see it first time on logs approx in 20 minutes will be node deleted and cluster will be down-scaled.
Then in logs after some time we can see that Autoscaler add taint to both nodes (he consider both of them as candidates for deletion).
I0203 13:25:18.149211 1 delete.go:103] Successfully added DeletionCandidateTaint on node Shoot--dev--mcm13-wrk-z1-6c765-gbjwm
I0203 13:25:18.157509 1 delete.go:103] Successfully added DeletionCandidateTaint on node Shoot--dev--mcm13-wrk-z1-6c765-wk8gr

In next 10 minutes you can see how one of the node is removed taint for second node released.
I0203 13:36:39.153508 1 scale_down.go:1102] Scale-down: removing empty node Shoot--dev--mcm13-wrk-z1-6c765-gbjwm
I0203 13:36:39.177325 1 delete.go:103] Successfully added ToBeDeletedTaint on node Shoot--dev--mcm13-wrk-z1-6c765-gbjwm
I0203 13:36:39.221217 1 mcm_manager.go:546] MachineDeployment Shoot--dev--mcm13-wrk-z1 size decreased to 1 shoot--dev--mcm13-wrk-z1-6c765-wk8gr - node group min size reached
I0203 13:36:49.189295 1 pre_filtering_processor.go:66] Skipping Shoot--dev--mcm13-wrk-z1-6c765-gbjwm - node group min size reached
I0203 13:36:49.189330 1 scale_down.go:917] No candidates for scale down
I0203 13:36:49.189359 1 delete.go:197] Releasing taint {Key:DeletionCandidateOfClusterAutoscaler Value:1675430718 Effect:PreferNoSchedule TimeAdded:<nil>} on node shoot--dev--mcm13-wrk-z1-6c765-wk8gr
I0203 13:36:49.203160 1 delete.go:228] Successfully released DeletionCandidateTaint on node Shoot--dev--mcm13-wrk-z1-6c765-wk8gr
W0203 13:36:59.216194 1 clusterstate.go:594] Nodegroup is nil for openstack:///5aed4bed-e5db-4bca-bc70-d13640ae5260
I0203 13:36:59.216240 1 static_autoscaler.go:341] 1 unregistered nodes present
I0203 13:36:59.216267 1 static_autoscaler.go:432] No unschedulable pods
In Shoot cluster you can see now only one node ready. Difference is that scaling down taking longer than scaling up because downscale is critical operation and autoscaler want to be sure that this decrease of load is not only temporary.

Manual Scaling
Manual scaling meaning editing yaml configuration manifest for shoots or editing Shoot object in Garden cluster.
It needs to be modified field shoot.spec.provider.workers.minimum to desired
number of nodes but value of field needs to lower or equal to shoot.spec.provider.workers.maximum
For down-scaling you will decrease shoot.spec.provider.workers.minimum value
to desired number of nodes (not lower than 1)
Example 2
Shoot name: mcm13
Number of nodes: 1
Node resources: 2 CPU 4GB Ram
Scaling configuration:
maxSurge: 1
maxUnavailable: 0
maximum: 3
minimum: 1
Gardener project name: dev
Name of seed namespace for Shoot: shoot--dev--mcm13
Name of garden cluster: pg-mcm1
Then edit object Shoot in Garden cluster.
kubectl edit Shoot/mcm1 -n garden-dev --kubeconfig <kubeconfig of pg-mcm1 garden cluster>
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: mcm13
…
maxSurge: 1
maxUnavailable: 0
maximum: 3
minimum: 1 --> 2 or 2 --> 1
When change will be applied by saving and closing yaml manifest of object reconciliation starts immediately.